目录
之前搞了个本周值得看的小周刊,准备收集一些遇到的有意思的文章、网站等,后来发现用码字的方式实在是过于麻烦了(其实是自己懒),所以想着有没有更便捷的方式,想起来以前用过的稍后再读,把文章收藏到笔记软件里面,于是就想自己写个网站,实现想要的效果,终于赶在年前上班的最后一天,把所有想要的功能全部实现了。
实现过程
开始的想法是,写个管理后台,在后台上传网址,然后写个爬虫自动抓取网页内容,再调用AI分析下网页内容并自动生成总结,最后将对应内容入库。功能还是很简单的,用Cursor也轻轻松松的生成了对应代码,后台再加了点增删改查,就初具雏形了。
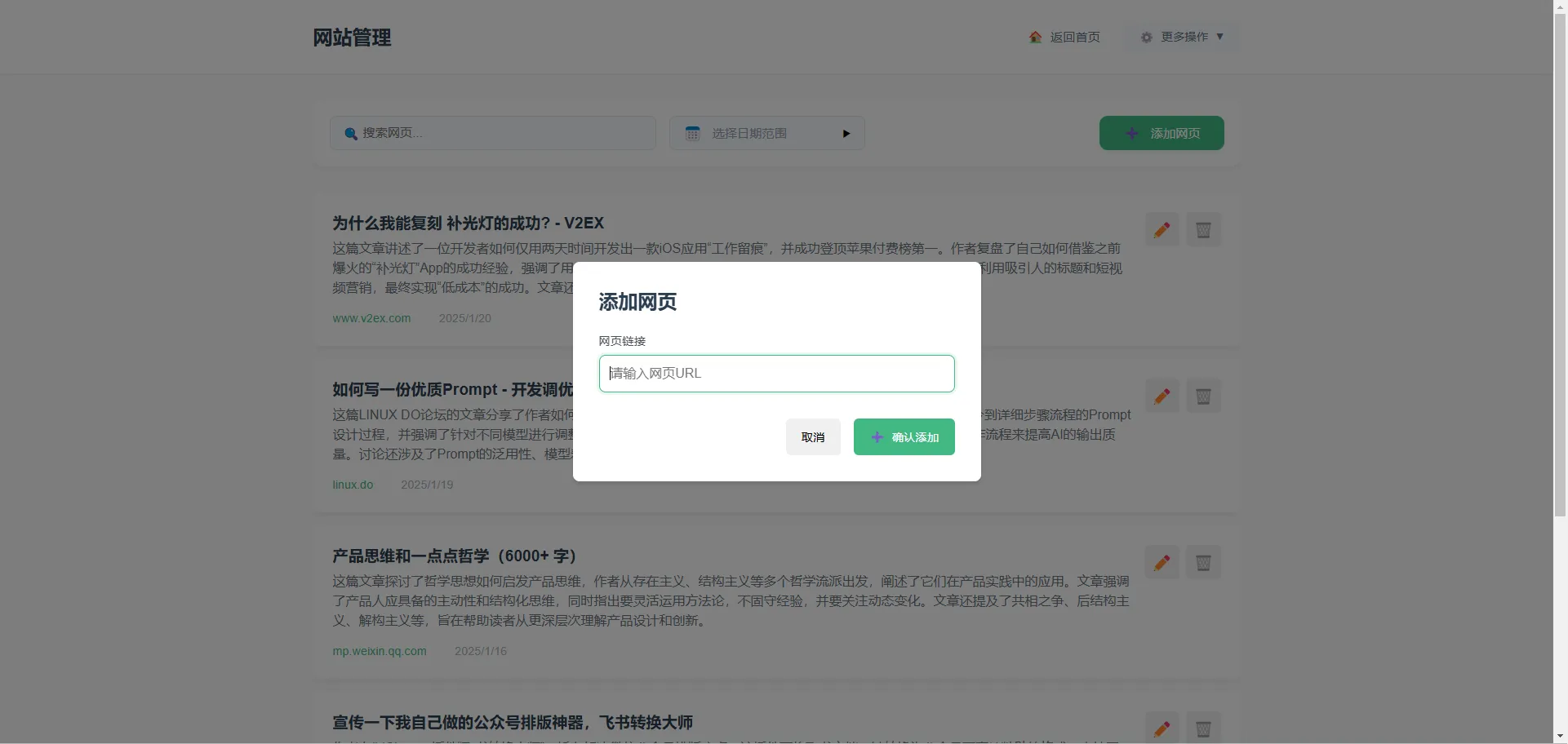
内容抓下来后,就开始调试展示的网页了,玄学调整了好几个版本,最后老老实实用内容卡片展示了,右侧简单加了搜索功能和日期筛选,最后再根据实际使用效果,修复了一些AI生成代码过程中的bug,也就差不太多了。
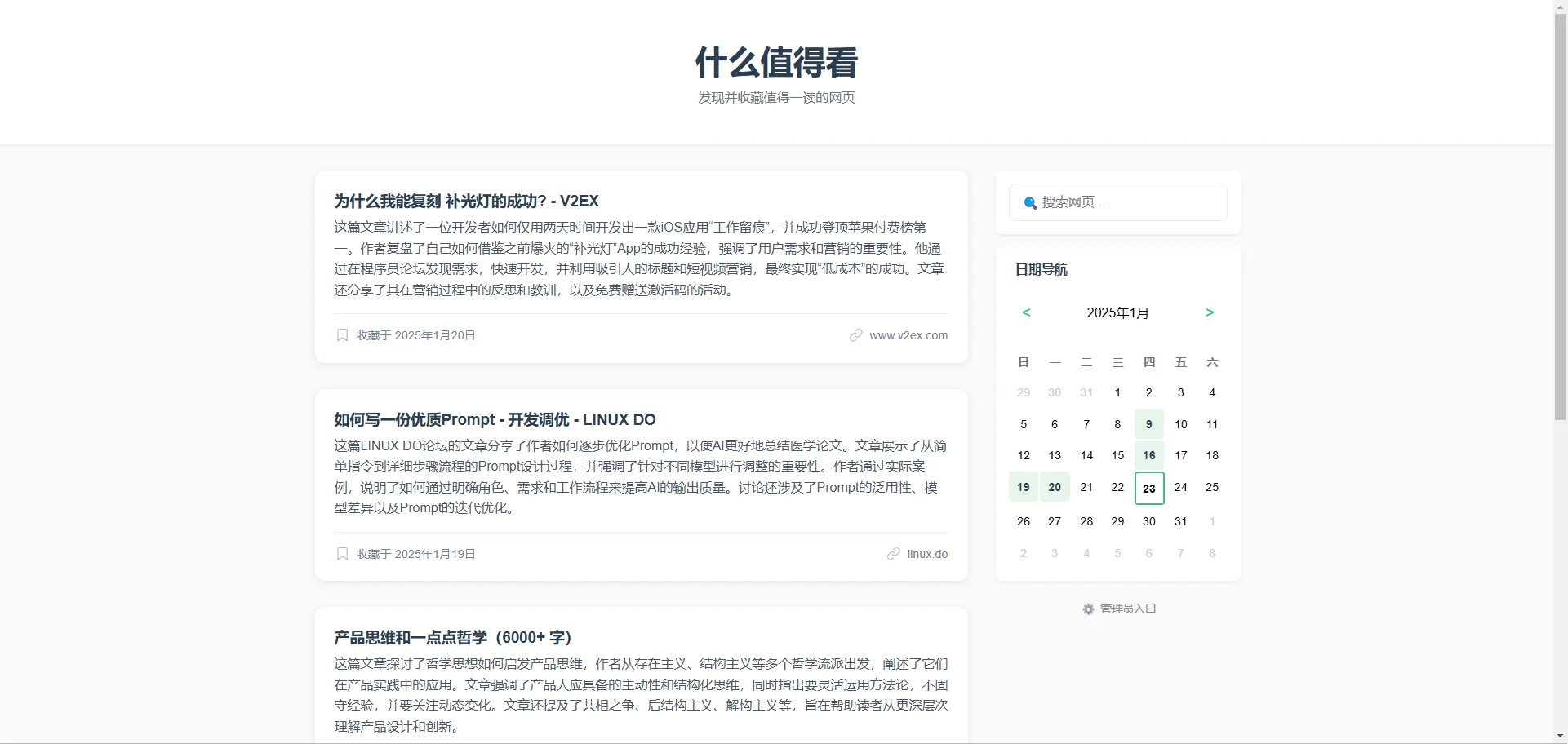
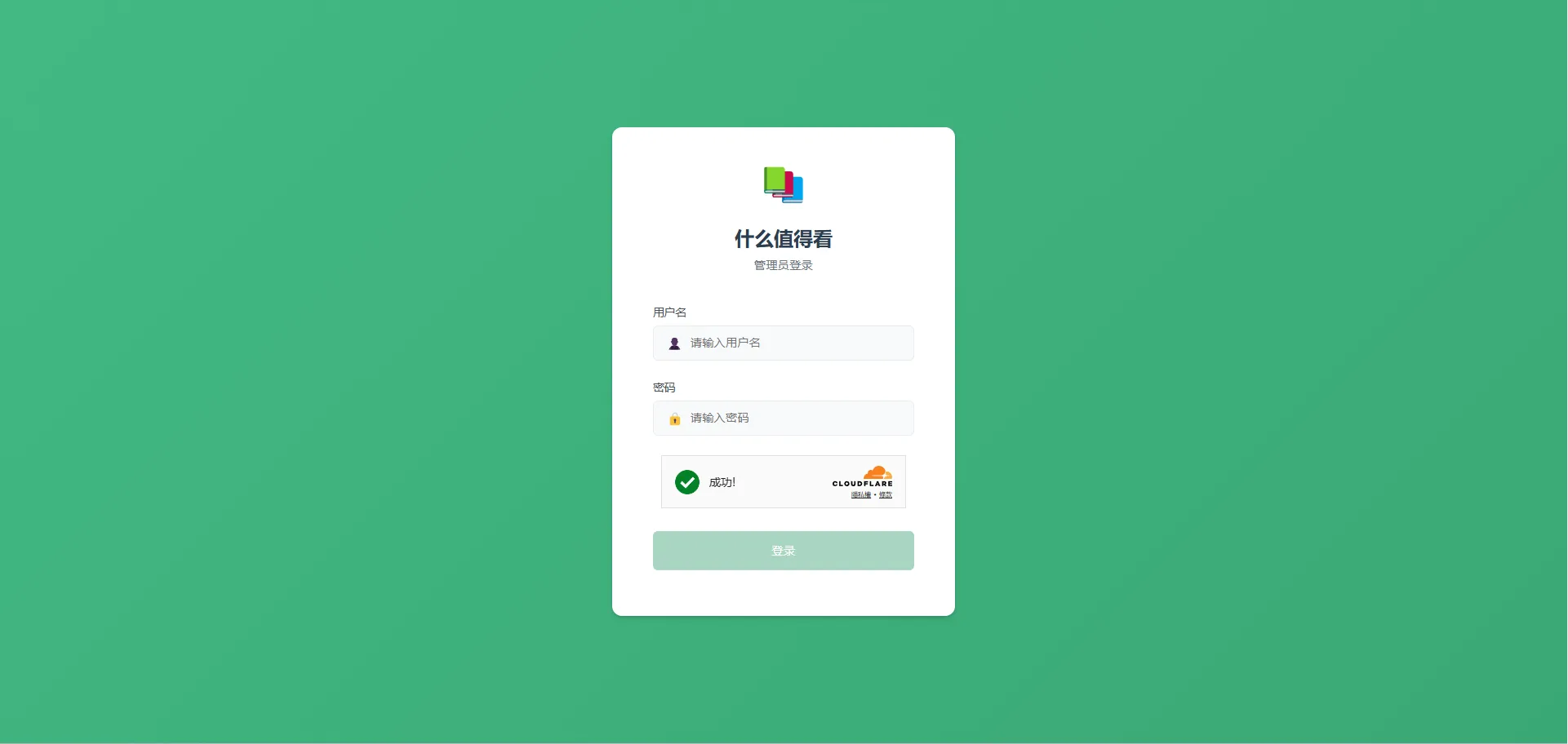
完成上面两个,已经算是有了基本的功能,准备上线的时候,就得考虑一些实际部署使用的问题了,继续加了一些登录、修改密码的功能,写了初始化数据库和重置密码的脚本,就把第一版扔到了线上。转头再一想最终这个网站会放到公网,就不得不考虑点安全问题,以前就想用Cloudflare家的人机校验组件Turnstile,这次就给加上吧,过程也很简单,就给Cursor说在登录页加上Cloudflare Turnstile直接就完事了。
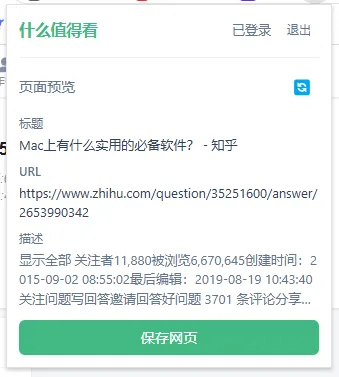
这个初始版本算是完成了,但是后续实际用的时候,发现个挺大的问题,有些网站的内容必须是登录才能看到的(这里点名批评知乎),光用简单的爬虫根本抓不到,要想完全用爬虫实现成本太高了。正好前段时间写了个屏蔽B站视频的浏览器插件,也算对浏览器插件开发有点了解了,用插件抓网页的内容然后再调用对应的后端接口实现这个功能,也太合适了,说干就干,于是又开发了个对应的浏览器插件。
目前使用下来,效果非常好,我自己也已经很满意了。这个收集站的链接 (https://read.diyun.site) 我也挂到了博客站点的顶部,感兴趣的可以点击看看。
一些总结
-
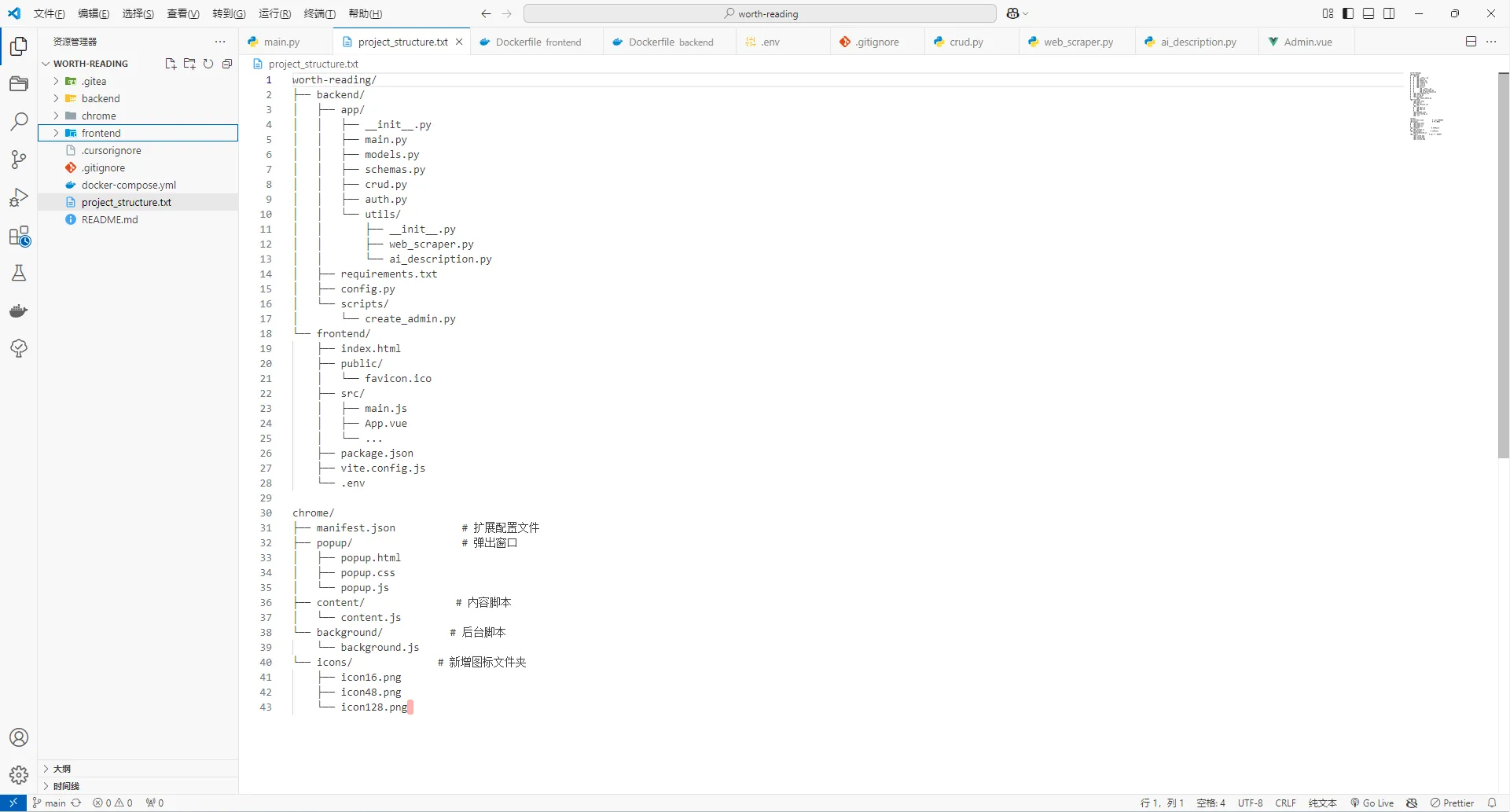
让cursor写项目前,最好先说一下自己的想法,然后让他规划一下代码文件结构,不然它随意生成的文件,可能会前后端杂糅,无论是前期开发还是后期部署都会十分麻烦,这是我先让他规划代码文件结构后再生成代码,Cursor实际生成的文件结构,还算十分科学。
-
有些想实现的效果,光靠平时说的大白话,可能AI调整半天也达不到最好的效果,但是一换专业术语,AI能马上反应过来并实现出来。例如下面右侧这个悬浮效果,前面一直就简单的描述「悬浮效果」,它的实现总是会有bug。正好刷抖音的时候,某个前端讲师教学「粘性布局」,然后灵机一动我就给AI说使用粘性布局实现,瞬间效果十分完美,没有任何bug。
-
如果不知道有些效果用专有名词怎么描述,其实可以再单开一个AI聊天窗口,用大白话给AI说,让AI用专业术语总结后再回复你,或者直接让AI给技术方案也可以,我在开发过程中就单开着一个deepseek作为辅助。
本文作者:狄云
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!